
Resource Monitoring for Developers
Motivation
For computationally intensive tasks, monitoring the workstation's resource usage is important. Said workloads can range from gaming, to high performance computing, or training deep learning models. Knowing how much CPU/GPU/RAM/network bandwidth is used can tell developers if their machines can handle the workload. If necessary, the developers can modify their code to reduce resource usage, or add more hardware to accomodate for the heavier load.
Monitoring Tools
Depending on the platform, different built-in solutions are offered. Linux users have the GNOME System Monitor, Windows users have Task Manager, and Mac users have Activity Monitors. Sadly, these off-the-shelf solutions share a few problems. They are quite inaccurate, their graphical interfaces are unfriendly, and their logs cannot be exported.
These tools are useful for taking a quick glance at the resource usage. Serious developers, however, would require more than basic tools. They often have to export their findings and share it with their colleagues.
Third Party Alternatives
There are many third-party tools catering to various platforms and needs. For example, GPU-Z for monitoring NVIDIA chips or s-tui for graphical monitoring on Linux terminals. My personal favorite monitoring tool by far is netdata.
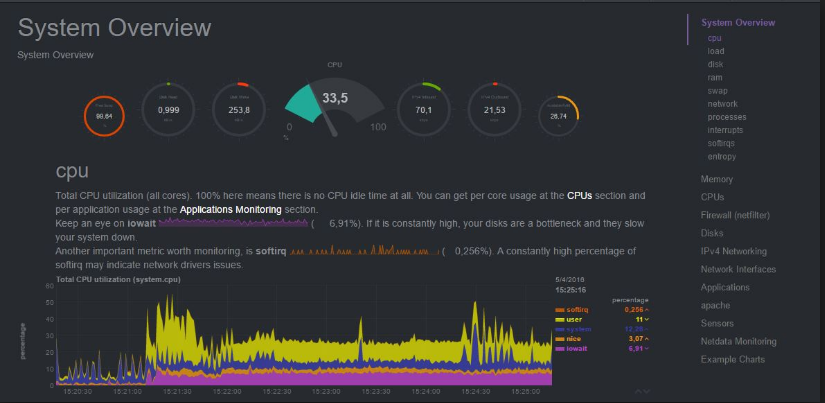
Netdata is a powerful open-source tool designed to collect a plethora of real-time metrics, and then displaying them on aesthetically pleasing, easy-to-interpret graphs and charts. Unfortunately, Netdata is not supported natively on Windows. Netdata's engineers decided to focus their effort on Linux, since that is what the vast majority of the production systems use. Windows developers have to jump through a bunch of hoops to use netdata with Windows (Just hop onto the Linux bandwagon already. Why would anyone still run production systems on Windows?). In the future, a whole post may be dedicated to just exploring Netdata.
I hope this post introduced you to some monitoring tools. If there is any takeaway, it is for developers to move away from built-in monitoring tools and adopt better third-party solutions. Feel free to share other monitoring tools that you used for your job.
Happy monitoring!


